최초의 칩렛 GPU, AMD RDNA3 아키텍처의 비밀과 전망

그래픽카드 시장에서 AMD는 만년 2인자 자리를 못 벗어나고 있다. 말이 좋아 2인자지 1위와 2위 뿐인 싸움에서 언제나 지는 것은 AMD 였다. 플래그쉽 경쟁에서 매번 뒤쳐지고 기술 트렌드를 끌고 가지 못했으니 어찌 보면 당연한 결과다.
하지만, 플래그쉽이 아닌 미들급 이하 시장에선 AMD도 선전해 왔고 그런 뒷받침 덕에 매번 새로운 아키텍처로 무장한 새로운 GPU와 그래픽카드를 내놓고 있다.
오늘 소개할 RDNA3는 AMD가 만든 최신 GPU 아키텍처다. 이미 시장에 투입된 RDNA2를 잇는 AMD의 차세대 GPU 아키텍처로, 이를 채택한 라데온 RX 7900 XTX가 엔비디아의 지포스 RTX 4080을 넘어섰다는 소식에 게이머들의 관심이 집중된 바 있는데 오늘 그 RDNA3에 대해 가볍게 알아볼까 한다.
■ RDNA3 GPU 아키텍처, 칩렛은 왜 도입했나?
AMD가 개발한 RDNA3 GPU 아키텍처는 최초의 칩렛 구조를 도입했다는 점에서 의미가 남다르다. 라이젠으로 대표되는 AMD의 CPU를 통해 처음 현실화 된 칩렛이 GPU에도 적용 됐으니 신기하기도 하고 기대감도 클 것이다.
AMD도 이런 구조의 도입으로 15% 더 높은 클럭과 54% 더 높은 전성비를 실현했다며 꽤 자랑스러워 했는데 아쉽게도 GPU 칩렛은 덩어리 하나를 분리한 것 그 이상도 이하도 아니었다.
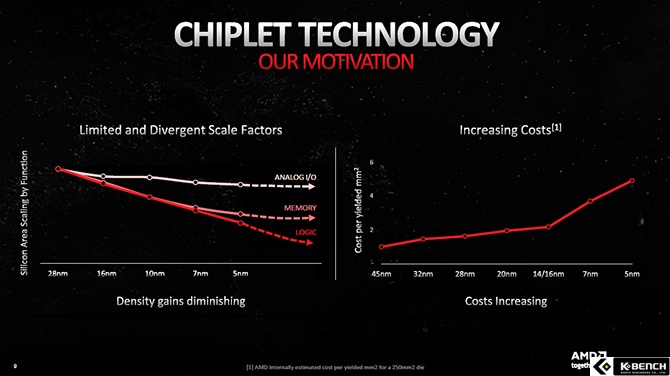
AMD가 RDNA3에 도입한 칩렛은 GPU에서 많은 면적을 차지하는 SRAM과 메모리 컨트롤러를 분리한 것이 핵심이다. 이 중 SRAM, 즉 캐쉬 메모리는 GPU에 종속되지 않은 여유분, 공식 명칭으로 하면 인피니티 캐쉬를 메모리 컨트롤러와 함께 분리해 냈는데 이 것은 반도체의 미세 공정 특성과도 연관이 있다.
AMD가 제시한 자료에도 나와 있듯이 반도체 공정이 미세화 되도 메모리와 I/O 로직의 밀도는 크게 나이지지 않는다고 한다. 순수 계산 영역은 미세화 된 공정을 사용하는 만큼 집적도와 밀도가 높아지지만 메모리와 아날로그 I/O는 큰 차이가 없다.
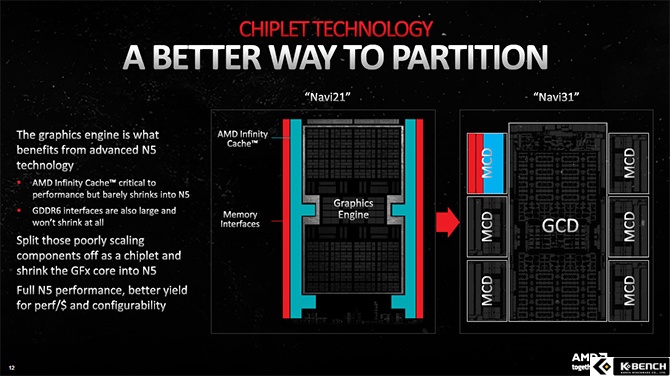
이렇게 되면 아무리 미세화 된 공정을 사용해도 캐쉬나 메모리 컨트롤러 같은 아날로그 I/O가 차지하는 비중은 늘어날 수 밖에 없고 그로 인해 생산 단가만 높아지는 문제가 생긴다. 그래서 AMD는 계산 로직만 최첨단 미세 공정을 사용하고 캐쉬와 메모리 컨트롤러만 단가가 저렴한 한 세대 이전 공정을 사용하기로 결정했고 이를 위해 필요한 기술들을 RDNA3에 도입해 완성해낸 것이다.
결국, RDNA3의 칩렛 구조는 생산 단가를 줄이기 위한 선택일 뿐 이를 통해 더 나은 성능을 실현하기 위한 것은 아니라고 볼 수 밖에 없다. 물론, TSMC가 7nm 이후 생산 단가를 크게 올렸다는 점에서 어쩔 수 없는 선택으로 이해할 수도 있겠지만 경쟁사는 여전히 모놀리식 싱글 다이를 고집하고 있다는 점에서 AMD의 칩렛 구조를 긍정적으로 평가하긴 어려운 상황이다.
앞서 발표된 CDNA2 처럼 GCD를 2개 묶은 멀티 GPU 구조를 위한 선택 였다면 칩렛 구조를 도입한 것이 어느 정도 이해는 되지만 GCD 1개로는 이런 비판에서 자유로울 수 없다.

참고로, AMD는 칩렛을 도입하기 위해 MCD와 GCD를 연결하는 인피니티 링크를 최적화 하는데 많은 투자를 했으며 이를 통해 라이젠과 EPYC에 사용하는 IFOP 보다 10배나 높은 대역폭을 제공할 수 있게 만들었다.
MCD가 외부로 빠지면서 문제가 된 지연 시간 문제도 페브릭 클럭 속도를 43% 높여 모놀리식 GPU인 NAVI21과 동등한 수준으로 낮춰 났으며 인피니티 캐쉬 지연 시간은 10%나 개선한 것으로 소개됐다.
■ 성능 향상, 무엇이 핵심인가?
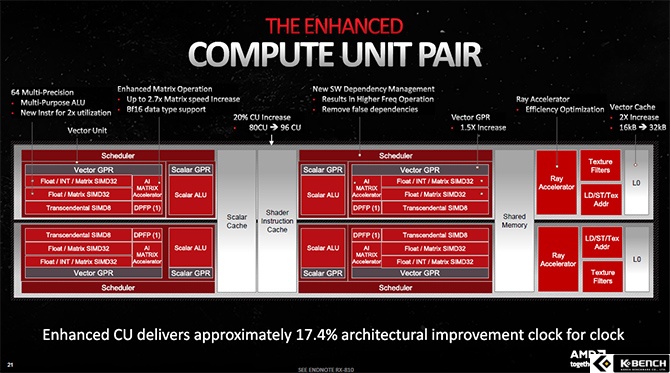
RDNA3 GPU 아키텍처에서 칩렛은 성능 향상과 거의 무관하다. MCD를 분리해 내며 발생한 문제들을 해결한 정도일 뿐이다. 그래서 성능은 칩렛이 아닌 GCD의 변화에 집중해야 한다. 특히, RDNA 시리즈의 핵신인 컴퓨트 유닛(CU)은 사실 상 GPU 성능을 결정짓는 부분이라 핵심 중의 핵심이다.
RDNA3는 그 핵심인 CU의 사이클 당 연산량을 2배로 늘리는 구조를 도입했다. 기본 구조는 이전 세대에서 이어져 온 그대로지만 32way SIMD 유닛을 2배로 확장했고 그 결과 사이클 당 처리 가능한 스레드도 2배 확장되게 됐다.
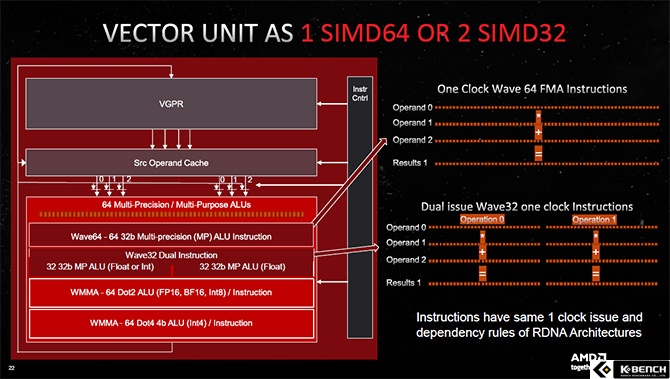
RDNA2에선 사용하지 않던 Wave 64도 다시 도입해서 사이클 당 두 개의 Wave 64까지 처리할 수 있게 됐는데 효율성 문제로 RDNA2에선 사라졌던 Wave64가 다시 도입된 걸 보면 그만큼 처리 능력이 향상 됐으니 게이밍이 아닌 GPU 기반 연산 작업에서도 더 나은 성능을 실현 했을 것으로 판단된다.
AMD는 CU 당 SIMD 유닛을 2배 확장한 것에 맞춰 L0와 L1 그리고 L2 캐쉬 용량과 대역폭도 크게 확장했으며 이전 세대에는 없던 WMMA 매트릭스 계산기도 추가했다. 이 계산기는 엔비디아의 텐서 코어와 유사한 행렬 곱셈 전담 유닛으로, 자세한 소개는 없었지만 AI와 딥러닝 같은 분야에 활용될 전망이다.
이 유닛 덕분인지 AMD는 FSR 3.0이라며 엔비디아의 DLSS3와 유사한 차세대 업스케일 기술을 개발하고 있음을 밝힌 바 있다.
■ 레이트레이싱은 여전히 하이브리드

AMD가 RDNA2에 도입한 레이트레이싱은 순수 하드웨어 방식은 아니었다. BVH(Bounding Volume Hierarchy) 기반의 교차와 순회 테스트 중 교차만을 판별할 수 있어 순회 테스트는 범용 연산 유닛에 의존하는 하이브리드 방식였다. AMD가 RDNA2를 개발했을 당시만 해도 레이트레이싱은 일부 AAA 타이틀에만 적용되다 보니 하이브리드 구조가 딱히 나쁘다는 비판은 없었다.
하지만, 지금은 레이트레이싱을 활용한 게임들이 많아졌고 프레임 문제를 개선할 업스케일링 기술도 발전되면서 순수 하드웨어 방식에 대한 기대가 높았는데 아쉽게도 RDNA3도 하이브리드 구조인 것으로 확인됐다.
RDNA3에는 여전히 RA라 명명된 유닛이 있고 이를 2세대로 진화했다는 내용만 있을 뿐이다.
그 중 핵심으로 소개된 DXR Ray Flags는 원래 DXR 1.1 사양에 포함된 명령이라 RDNA3만의 장점이라 말하긴 어려운 부분도 있으나 이를 하드웨어로 관리하는 방식을 통해 순회 루프 인터렉션 명령어 개수를 15% 가량 줄였다고 한다.
여기에 더해 하드웨어 기반 박스 소팅 모드를 통해 다른 광선 타입의 순회 인터렉션 회수를 줄일 수 있게 했으며 새로운 2단계 스케줄링 알고리즘을 도입하여 빈 광선 쿼드를 버리고 광선당 사이클을 최적화하는 기법도 도입한 것으로 소개됐다.
AMD는 이런 변화를 통해 종전 보다 1.8배 향상된 레이트레이싱 성능을 제공한다고 밝혔다.
■ AMD에 고마워 하자, 가격 인하의 신호탄이 되길..

AMD는 RDNA3로 만든 라데온 RX 7900 XTX와 7900 XT를 오늘 밤 공개할 예정이다. 여기서 말하는 공개는 내부 모습과 성능 데이터가 모두 포함된 벤치마크와 리뷰를 말하며 이를 통해 AMD가 주장한 지포스 RTX 4080을 넘어선 성능이란 걸 입증하게 될 것이다.
아마 이변이 없는 한 AMD의 주장은 사실로 증명될 것으로 예상되는데 레이트레이싱 성능에 약간의 부족함은 있더라도 평가는 상당히 좋을 것 같다. 엔비디아가 지포스 RTX 4080 가격을 1,199달러로 정해 논 상황에서 라데온 RX 7900 XTX를 999달러에 판다고 했으니 결과는 안 봐도 비디오다.
하지만, 엔비디아가 지포스 RTX 4080 가격을 내리겠다면 라데온 RX 7900 XTX의 앞날이 순탄하리란 보장은 사라지게 된다. 라데온 RX 7900 XTX가 깡 성능도 좋고 전성비나 12VHPWR 커넥터 문제도 없지만 여전히 선호도 면에선 엔비디아에 밀리는 건 사실이기 때문이다.
어차피 결말은 오늘이 지나면 알게 되겠지만 게이머들 입장에선 자신이 선호하는 제품을 더 저렴하게 구할 수 있으면 그만이니 엔비디아와 AMD의 이런 경쟁은 무조건 환영해야 하고 그 결과를 즐기면 그 뿐이다.



댓글
댓글 쓰기